“To be a better girl ”
A Unified Probabilistic Framework for Name Disambiguation in Digital Library
Jie Tang,A.C.M.Fong,Bo Wang,and Jing Zhang
综述——前人工作——建模——实验——结论——其他
1. 综述
Question:
致力于解决数字图书馆中检索过程中的重名消歧问题
- prev
- 重名消歧的效果有上升的空间
- 没有自动估算出Number K或者估算效果不是很理想
- this
- 在综合考虑论文的属性和论文之间的关系的基础上用概率的方式建立一个统一的框架
- 两步模型参数估算算法
- 动态准确的方法发现number K
Question:
- 什么叫统一的概率框架?
- 什么叫Number K
2. 前人工作
方法
-
基于监督学习:
对数据进行处理,即人为贴上标签,然后用某些分类算法进行训练,最后预测测试集。即预测某个paper到底是对应哪里一个同名的作者
-
基于无监督学习:
用聚类算法或者主题模型对所有的paper进行划分类别,不同的类别就属于不同作者
-
基于约束学习:
本质上也是聚类算法去实现,只是在此基础上人为添加一些约束引导聚类
重名消歧的当前研究成果:
- 基于作者角色的方法去消歧
- 基于交互反馈然后用给定的搜索文本约束用户搜索
- 基于拓扑图的方法:通过论文引用,合作作者的关系图
- 基于不同方法然后进行整合各类方法建立一个框架去消歧
局限性:
-
图聚类算法考虑的因素较为单一:或考虑node,或考虑拓扑
如何平衡不同特征的权重,特征值少
- 以上方法基于准确的估计值 K 或者自动发现的K值的应用效果不理想
- 现存方法大多基于同质节点和关系,但现实中存在很多异构关系,不同类型的关系可能有不同的作用,如何估计不同关系的贡献
3. 建模
主要思想
综合考虑到拓扑图的node多个属性与边之间多样关系,并将这些用于隐马尔可夫模型。采用一个二步法估算参数和一个自动发现K值的算法。得到一个模型。然后通过模型计算出某个paper属于某个作者的概率。(采用无监督的方式)
隐 Markov 随机场
- 将基于内容和解构的信息包含到 隐马尔科夫随机场模型 作为一个特征函数
- 不同关系类型也模型化为权重与相关特征的函数
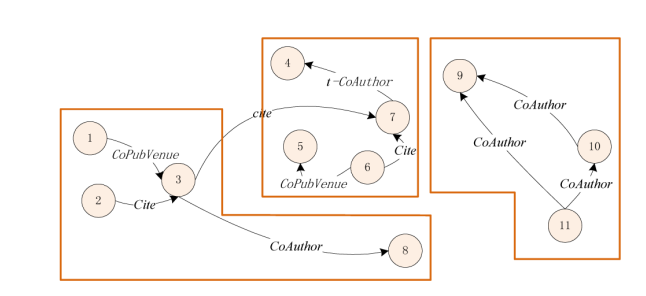
问题形式化
-
定义一
-
定义二
Cluster Atom(聚类原子)
-
定义三
第一作者与第二作者
公式推导
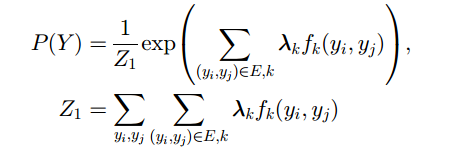
-内容出版服从高斯分布-
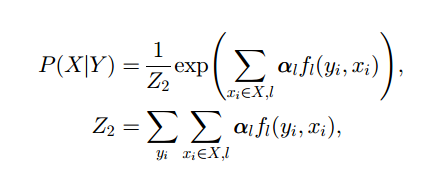
–
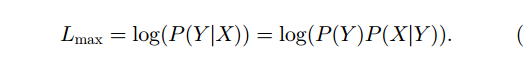
–
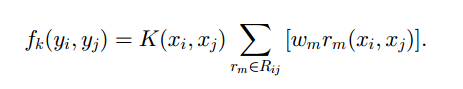
-
X
发表集合 P
-
xi
论文 pi 的向量 v(pi)
-
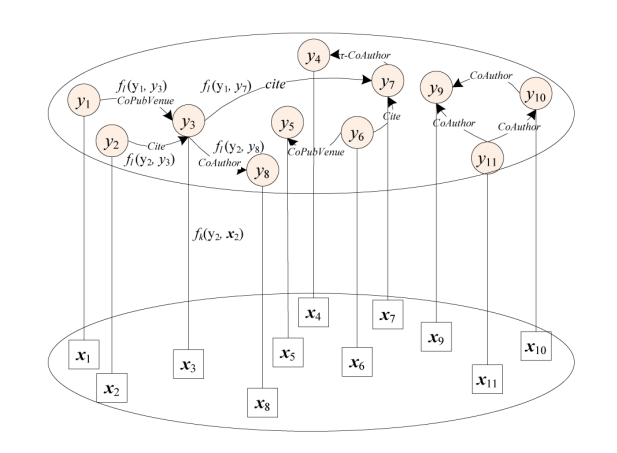
fl(yi, xi)
- 节点的特征函数,捕捉 paper xi 的特征信息
- 如果该论文与一个簇中其他的论文都相似,则很有可能属于该簇
-
fk(yi, yj)
边的特征函数
-
K()
xi 和聚类中心的相似度
-
\lambda \arfa
边特征函数和节点特征函数的权重
-
Z1 & Z2
归一化因子
-消歧目标函数-
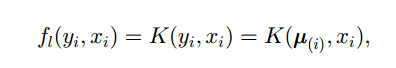
-
最大化 P(Y X) - P(X) 常作为约束
根据贝叶斯,目标函数可化为
–
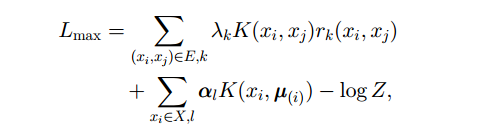
动态K算法
目标: 取得最大化目标函数的 K
贝叶斯方法

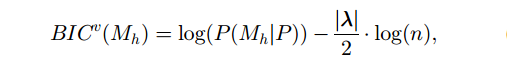
参数估计

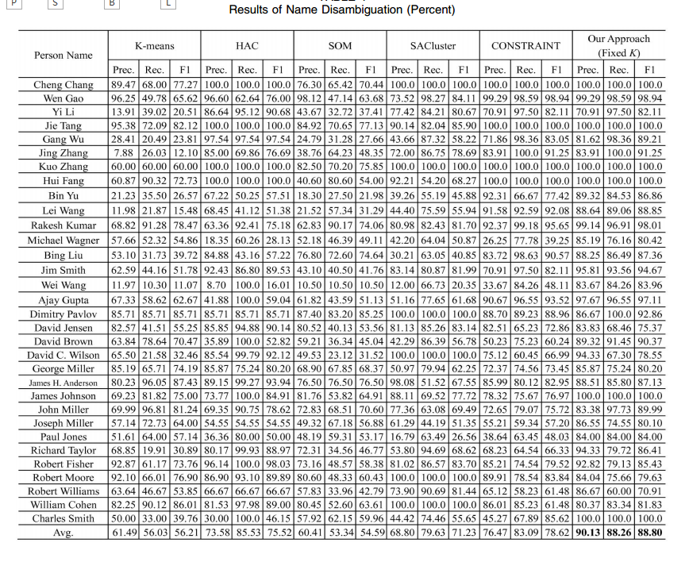
4. 实验
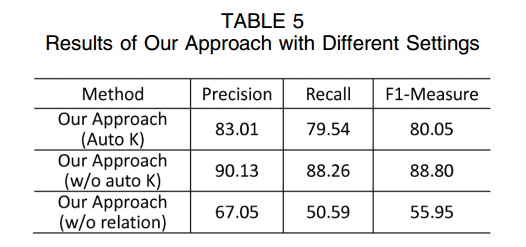
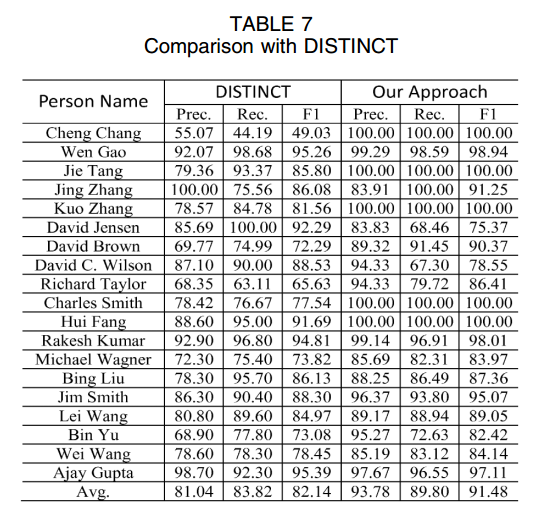
5. 结论
该论文主要是为了解决重名消歧问题。
- 作者综合考虑到了文章的内容(node属性)和文章之间的关系的类型。
- 在隐马尔可夫模型的基础上,基于上述的特征属性进行消歧。
- 该文章的创新之处还在于发明了一个参数估计的二步法
- 以及一个动态发现K的算法
future work
- time
- topic