“To be is to be perceived. ”
- 如何读论文
- 关于消歧
- 论文
- 1. Embedding of Embedding (EOE) : Joint Embedding for Coupled Heterogeneous Networks
- 2. Name Disambiguation in Anonymized Graphs using Network Embedding
- 3. Modeling Mention, Context and Entity with Neural Networks for Entity Disambiguation
- 4. Deep Neural Networks for Matching Online Social Networking Profiles
- 5. Author name disambiguation using a graph model with node splitting and merging based on bibliographic information
如何读论文
读前判断
- 看摘要和 introduction 最后一段
- 看结论
- 浏览公式图表
若适合,开始阅读
阅读
- 标题——必懂
-
扫摘要
看是否符合自己领域
-
introduction
了解文章主题
- 实验对象
- 已有研究
- 现存问题
-
主要问题、假设、解决办法
为解决问题提出了什么,打算从哪些方面验证(概述方法),便于有目的性的看实验方法
-
- 自己贡献
- method
- 将方法用流程图表现
-
result
- 看table 和 figure (注意图表注释)
- discusssion
- 子标题一般为结论或新发现
读后
- 对着笔记可以看出文章核心
思考
- 该实验和数据,是否解决了问题
- 为了解决问题而提出的假设是否合理
- 用自己语言总结该 paper 的发现
摘要
- 与自己总结的结论相对照,看是否理解正确
关于消歧
消歧方法
-
学者特征
- 通过选取有较大区分度的学者相关属性特征信息,优化并得到最好的特征集通过算法进行消歧
- 但由于学者信息特征缺失或偏差常常不能达到良好的消歧效果
-
机器学习
目标是建立文献与现实中实体的对应关系
-
基于监督
根据人工标注的数据,主要包括学者姓名、文章标题等属性信息,生成分类模型,用其判断相同学者名字是否属于同一个学者实体
-
基于非监督
用属性计算记录间的相似度,根据相似度进行聚类
-
基于半监督
-
-
社会网络
根据学者和其文章间的合作引用关系建立的网络挖掘其节点特征,将待消歧人物关系用社会网络来表示,通过局部网络得到其相似度再经由聚类划分
-
网络资源
利用网络公开资源,建立消歧对象与网络资源之间的联系,充分挖掘人物信息,从而得到更丰富的人物特征,达到消歧目的
按特征选取类型
- 全文名词短语
- 基于摘要的名词短语

- 合作程度:
- 共同合作者越多,对待消岐作者识别能力越强
- 直接合作者识别能力 > 间接合作者
-
评价标准:
准确率、召回率、F1值
已有工作
学术社交网络
研究热点
- collaboration
- performance
- behavior
- social network
- innovation
- community
- knowledge
网站资源推荐研究
-
合作者推荐
- 中科大的杨辰博士将基于相似性的合作者推荐方法与以专业知识覆盖面为导向的推荐方法相结合
- 提出了基于情景优化的科研合作者推荐模型
- 中科大的杨辰博士将基于相似性的合作者推荐方法与以专业知识覆盖面为导向的推荐方法相结合
- 团队推荐
- 汤庸教授团队在学者网建设过程中提出了 面向学术社交网络的多维度潜在团队推荐模型(MFTR)
- 通过投影梯度非负矩阵分解法提取团队和用户特征向量 并融合用户的社交好友关系和热门团队信息为用户推荐具有相似研究兴趣的潜在团队
- 科研论文推荐
- 孙见山博士提出了一个集成的科研论文推荐框架 为学术社交网络上的科研人员提供论文推荐服务 并将原型系统成功运用于科研之友网站上 有效促进了科研人员间的资源共享与项目合作
- 学习资源推荐
- 遥俞琰提出了一个融合社交网络信息的学习资源推荐算法 根据用户浏览过的学习资源和用户间的社会网络关系为用户进行个性化学习资源推荐,旨在帮助研究者快速发现有价值的学习资源
消歧
- 聚类
挑战:
-
数据库动态变化
现有大部分消岐方法只针对静态数据集
- 大多数方法建立在两点假设:
- 研究者一段时期内有比较稳定的合作者
- 研究者一定时期内研究方向,兴趣等不变
-
数据分布不均衡(导致聚类不理想)
一个作者论文很多,其他同名作者很少
-
文献特征属性作用不同
合作者、email等强特征和标题、摘要等弱特征(可用分布聚类)
- 信息不全——属性信息丢失
- 语言差异
-
增量消岐
加入新数据时仍有很好的消岐效果,而不是每一次重新加载数据时进行一次完整的消岐
- 新增作者
- 学者隐私
论文
1. Embedding of Embedding (EOE) : Joint Embedding for Coupled Heterogeneous Networks
- 不同类型的相关信息可以融合在一起形成异构网络
- 网络间的边缘可以作为网络内部边缘的互补信息(使得潜在的特征更加全面和准确——冷启动问题)
- 使用一个联合嵌入矩阵将两个异构网络的潜在特征从一个空间变换到另一个空间
2. Name Disambiguation in Anonymized Graphs using Network Embedding
- 以匿名图的形式利用关系数据
- 学习方法:将每个文档嵌入到低维向量空间,可通过凝聚层次聚类算法消岐 3.利用 人-人、人-文、文-文、三个图(用唯一的伪随机标识符表示),将三个图中的累计特征结构编码,到一个网络嵌入模型,为每一个文档生成一个K维向量表示
- 基于排序的损失函数作为目标函数
3. Modeling Mention, Context and Entity with Neural Networks for Entity Disambiguation
目标:
给定词:president obama 和文档:After campaigning on the promise of health care reform, President Obama 将提及到的词 对应到 维基百科中一个实体
贡献:
- 提出新的神经网络方法:有效捕捉提及语义、上下文和实体
- 结合上下文单词及其位置信息与卷积神经网络结合,并利用低秩神经张量网络对提及和上下文见语义构成进行建模
现有工作主要使用手工特征表示提及、内容和实体(工作量大且难以发现数据的解释因子)
神经架构图:
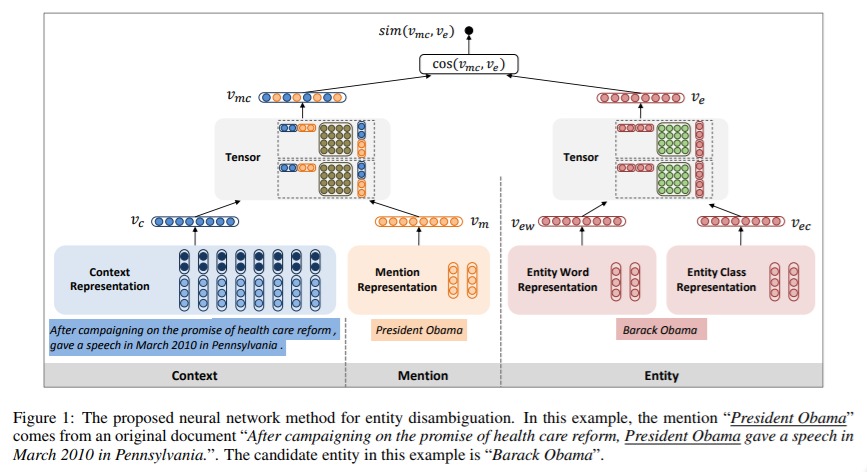
- 将实体消岐作为排名任务:通过对比输入(提及、上下文)和候选实体间的相似性
- 输入:上下文、提及、实体
- 输出:候选实体和提及、上下文的相似度
- 在连续的向量空间嵌入提及、上下文和实体以捕获他们的语义表示
- 用卷积神经网络学习上下文单词的连续表示(及候选实体的连续表示)
- 加入上下文单词和连续向量空间中提及内容间的距离(距离近的上下文单词更重要)
- 用神经张量网络提出语义组合
- 将上下文、提及、实体的学习表示用于计算其相似性
上下文建模
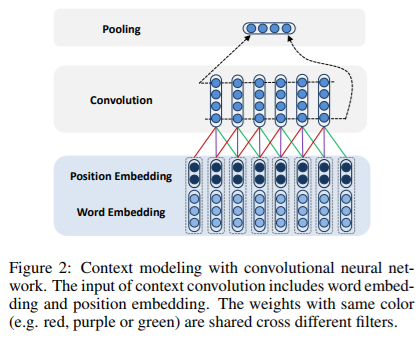
上下文词向量(词嵌入+位置嵌入)通过卷积神经网络产生固定长度的向量
提及建模
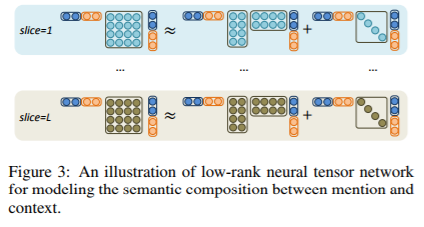 input : 提及向量+上下文向量
input : 提及向量+上下文向量
实体建模
考虑:实体表面词、实体类(参考知识库中提供的词或短语表示实体分类信息) 如: Barack Obama :表面词(Barack 和 Obama),实体类(president of the united states)
产生:实体词向量、实体类向量
实体消岐:计算上下文提及对每个候选实体间的相似度,选择最接近的 损失函数思想:正确的实体输出评分>随机选择的候选实体评分
4. Deep Neural Networks for Matching Online Social Networking Profiles
5. Author name disambiguation using a graph model with node splitting and merging based on bibliographic information
-
基于图的姓名消岐方法
- 使用合作关系构建图模型,基于图节点分合/合并图以解决作者模糊性,只依赖书目信息(标题,出版社等)和共同作者
- 作者消岐图形框架(GFAD):
- 同名: 拆分参与多个环的作者节点
- 异名: 合并具有相似特征的多个作者顶点(若有连接到共同节点)
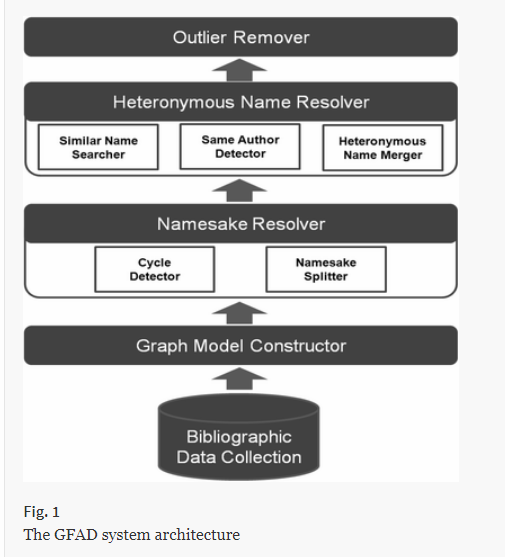
消岐过程
-
利用书目信息将作者间关系构建成图
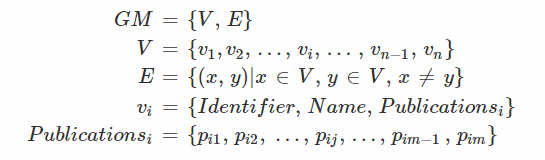 pij: vi中所有出版物的集合
pij: vi中所有出版物的集合 - 分割处于多个环中的作者解决同名
假定处于多个非重叠最大社交圈的人为同名的不同作者
- 检测图中每个节点的最长非重叠环
- 根据环进行节点分隔
如果一个环是其他的子集,则移除(4-10),检测合并共享同一顶点的环(11-21) 算法1:得到最长非重叠环; 算法2: 分割节点


- 合并同一个作者的不同表达解决异名 共享同一作者关系的相似名字为同一人 如果所有成员中至少一个公共节点,则判断为同一人
-
根据离群点与具有相似作者间的代表性关键词进行相似度度量(与最相似的合并) 使用文章中的词汇构成一个特征向量作为关键词做相似性度量 数据集:来自DBLP Arnetminer,处理后的精华集合
- Name Disambiguation from link data in a collaboration
节点: 名字实体
- 边: 不同名字实体间的合作(时间标记表示协作发生的时间)
使用无监督方式为节点评分,表示其纯粹程度(越小,模糊性越大),可用其作为预过滤器识别目标节点
G=(V,E) Gu=(Vu, Eu)<G - 假设:若u为多个节点,则一旦何其邻边被删除,则会形成多个不想交的簇(存在时间和领域变换的影响)
- 过程:
- 构造自我网络(由节点u和其相邻节点构成)预测多节点的可能性
- 用图形聚类算法聚类:使得不同聚簇的邻边最少(马尔科夫聚类)
- 去掉u: 找出u的邻居在没有u做中介的情况下是否依然紧密连接
- 边: 不同名字实体间的合作(时间标记表示协作发生的时间)
使用无监督方式为节点评分,表示其纯粹程度(越小,模糊性越大),可用其作为预过滤器识别目标节点
聚类评估:
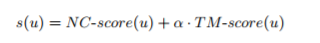
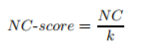
NC: 给定匿名实体的纯度
边缘权重和/所有边的权重,k为簇数(越小,越可能为多个节点)
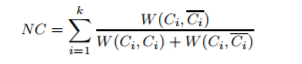
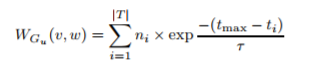
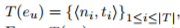
- 表示在Gu 中捕捉的 v,w的合作事件:
- ni 是 ti 时刻的协作事件数量,可使用指数衰减函数计算u 和 v之间的相似度(最近的协作事件更重要 tmax 表示最近的协作时间)
-
TM(temporal mobility)
实体随时间移动的可能性,反应节点在不同时间与不同邻居协作程度

4.时间协作矢量zi, 表示及群众的实体与时间轴上u间的关联权重